(c) 2008, MindTree Ltd. All rights reserved.
Design patterns – including architectural patterns - offer reusable solutions to design problems and are an established technique for efficiently and effectively solving design problems.
Over the last several years, they have steadily gained prominence in the realm of OO design. However, despite its established success in the OO world, I am surprised to find that no formal definitions exist of database design patterns. Data modeling – like software architecture and design –is characterized by ‘patterns’ that can be abstracted and effectively reused. In the current state-of-the-art in data modeling, the STAR and snowflake schemas are perhaps the only and best examples of use of patterns in data modeling. For OLTP systems though, there are no such pattern definitions. There exists literature and templates that serve as "common metamodels" for different verticals – e.g., insurance, banking, retail, supply-chain, etc. While these are useful to jump-start the data modeling for applications specific to those verticals, there exist patterns in data modeling that are independent of business verticals and RDBMS platforms.
The rules of ER modeling lay down guidelines for identifying entities and the structural relationships between them. ER modeling offers different constructs to address the complexity of data modeling and lays down a structured and scientific approach to defining data models.
Yet, while database design focuses on the structural aspects of the design, there are frequently occurring patterns that bring different structural design elements together to solve data modeling patterns.
The Template-Instance Pattern
The "Template-instance" pattern is used to capture definitions of a template that would be used to create different instances. This pattern allows user-defined definition of a structure to capture data at run-time as opposed to design-time definition of the data model. Among other applications, two possible uses are in a hosted application in the definition of a workflow. In case of hosted applications, this pattern allows users (e.g., an administrative user) to create their own templates for data capture and other users can use that template to populate data. In case of a workflow definition, users may want to setup their own workflow stages and properties for each stage such as notifications, constraints and so on.
Example
Consider a scenario likes SALESFORCE.COM which would want to allow organizations to define their own templates for account definition. As a simplification, let us assume that each organization must chose from a library of available fields.
Given three hypothetical organizations - Acme Technology Services, Terra Property Consultants and Universal Exports - SALESFORCE.COM would have to allow each organization to create their own template for account definition. For instance, all 3 would need to capture details like name, contact person, contact address, etc. but each would be interested in account details that are specific to their domain. Acme Technology Services for example may want to capture details like primary technology used (.NET, Java), industry vertical (Financial Services, Automobiles, Manufacturing, etc.) while these would be irrelevant for Terra Property Consultants and Universal Exports. Instead, Terra Property Consultants would be interested in fields that describe the real estate (commercial vs. residential, open land vs. built-up, etc.).
The "template-instance" pattern will provide for storage of a template which will then serve as a lookup for creating different accounts. The template itself would be stored in one table and accounts based on those templates in another table and there may not necessarily be a relationship between the two.
The same illustration can be extrapolated to a workflow definition scenario.
ER Construct
The template-instance pattern usually - but not necessarily - involves an intersecting entity. A relationship between the template entities and instance entities is not required and usually not present, but may be implemented for traceability.
Fig. 1 below illustrates the Entity-Relationship model that implements the template-instance pattern for the example described above.
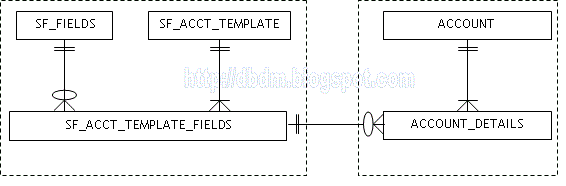
Fig. 1 - ER Model for the Template-Instance Pattern (SalesForce.com example)
In the figure:
- SF_FIELDS: Is the library of all fields
- SF_ACCT_TEMPLATE: Stores the account-definition template (fields for the template are stored in a separate table)
- SF_ACCT_TEMPLATE_FIELDS: Intersecting entity to resolve the M:N relationship between SF_FIELDS and SF_ACCT_TEMPLATE. This entity captures the fields for each account template.
Key Characteristics
- Caters to scenarios where data model is not available at design-time
- Templates as well as instances of the template are created by end-users at run-time
- Template definition serves as a look-up table to define the instance but there is no relationship required between the template entities and the instance entities. A relationship if any, only serves traceability purposes and no other.
The Master-Slave Pattern
The master-slave relationship captures an 1:M identifying relationship – i.e., a 1:M relationship where the existence of the entity at the "M" end is entirely dependent on the existence of the entity at the "1" end. The abstraction of a master-slave relationship involves normalization to 1NF. It models scenarios where an entity has common, descriptive information (the master) and details or line-items each of which has a common structure (the slaves).
Example
In the example on the Template-Instance pattern, the relationship between the "instance entities" ACCOUNT and ACCOUNT_DETAILS is an example of a master-slave relationship, where ACCOUNT is the master and ACCOUNT_DETAILS is the slave.
Another example that occurs very commonly is INVOICE and INVOICE_LINE_ITEM. In this case, INVOICE captures common information about the transaction such as invoice date, location, customer name, salesperson’s name and other aggregate information such as total number of items, invoice total, total discount, etc. Whereas, INVOICE_LINE_ITEMS captures the individual items sold in the transaction and each line item has a common structure. In both the above examples, the existence of the slave is entirely dependent on the existence of the master - i.e., if an account is deleted, all associated account details will also be deleted. Conversely, an account detail cannot exist without a corresponding account.
ER Construct
The master-slave relationship is modeled as a 1:M relationship, one-mandatory at the "1" end and many-mandatory at the "M" end. The entity at the "1" end is the master and the entity at the "M" end is the slave.
Fig. 2 below illustrates two examples of the master-slave relationship
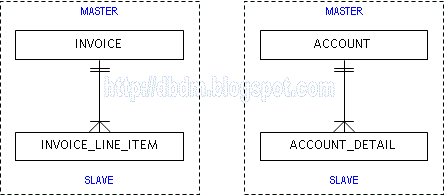
Fig. 2 - ER Model for the Master-Slave Pattern
Key Characteristics
- Implies normalization to 1NF
- Master:Slave is a 1:M relationship mandatory at both ends. The relationship is an identifying relationship – i.e., existence of the slave is dependent on the existence of the master.
The Lookup-Table Pattern
Lookup tables are used for storing data that requires persistence and has bearing on the application but no structural relationship with any of the other data in the database. Application parameters, settings used by triggers and stored procedures and reference data are the most common examples of data that necessitate a lookup table. For example, foreign-exchange rates in a banking application may have relevance to the calculations but have no structural relationship (as does a foreign key, for instance) with the rest of the database.
Data in a lookup table is usually organized in a name-value structure, with the name being unique. It is usually fairly static or subject to scheduled updates and is usually cached in the application-tier for faster access.
The Audit-Trail Pattern
Audit trails are used to capture change history of a given table. These are particularly useful in the context of financial applications or data that has financial implications, but in general, are used in any scenario where changes to data need to be tracked. The table storing audit trail information has the same structure as the original table along with additional housekeeping information such as timestamp of the change, kind of operation performed (UPDATE/DELETE) and the identity of the individual making the change. If there are special requirements known at design time that motivate the need for an audit trail, these may be provided for in the data model.
For example, if there is a frequently-accessed application feature that compares the old value with the new value, it may be easier to provide for this in the data model and populate this data while populating the audit trail. This will make retrieval and presentation easier since the data can be retrieved with a simple query.
The primary key of the original table exists in the audit trail table but does not function as the primary key. A surrogate key may or may not be generated for an audit trail table. Queries on the audit trail table are commonly based on either the primary key, date range, identity of individual permitted to make changes, the kind of operation performed (UPDATE/DELETE) or a combination of these.
Audit trails are usually populated through triggers. There are usually no constraints defined on the audit trail table. This is usually a trade-off on which the database designer and other key technical stakeholders have to make a judgment call – the trade-off is between ensuring tight data integrity and introducing overheads on the UPDATE/DELETE operation on the original table on which the audit trail is based. Retrieval and presentation of change history can range from straightforward to complex depending on the purpose of retrieving change history.
For instance, in scenarios where the last 5 changes made need to displayed in say, a pop-up from a main window, the query may be rather simple. However, additional requirements like comparing old and new values must either be pro-vided for in the data model or may require complex SQL queries to be written or some application-tier processing to display in columns, data retrieved in rows.
Example
In the SALESFORCE.COM example described in the "Template-Instance" pattern, consider the ACCOUNT table. An audit trail on that table could possibly be through an ON-UPDATE and ON-DELETE triggers that capture metadata of the change operation.
See the following illustration of how the audit trail may be handled. (Ignore syntax errors, normalization considerations and missing constraint definitions, if any in the DDL and DML statements. Also ignore apparent incompleteness of the data model if any.)
CREATE TABLE ACCOUNT (
ACCOUNT_ID INTEGER PRIMARY KEY,
ACCOUNT_NAME INTEGER NOT NULL,
ACCOUNT_CODE CHAR(5) NOT NULL,
ACCOUNT_TYPE VARCHAR(10) NOT NULL,
ACCOUNT_OPEN_DATE DATE NOT NULL DEFAULT SYSDATE,
ACCOUNT_STATUS VARCHAR(10) NOT NULL DEFAULT ‘ACTIVE’,
ACCOUNT_SALESPERSON VARCHAR(30) NOT NULL,
-- Y/N flag for deleted records. ‘Y’ = deleted
IS_DELETED CHAR(1) NOT NULL DEFAULT ‘N’,
CREATED_BY VARCHAR(10) NOT NULL,
CREATED_DATE DATE NOT NULL DEFAULT SYSDATE,
CREATE_REMARKS VARCHAR(100),
--
-- These can be updated either by the trigger
-- or by the application
LAST_UPDATED_BY VARCHAR(10),
LAST_UPDATED_DATE DATE,
LAST_UPDATE_REMARKS VARCHAR(100)
); CREATE TABLE ACCOUNT_HISTORY (
ACCOUNT_HISTORY_ID INTEGER PRIMARY KEY, -- surrogate key ACCOUNT_ID INTEGER, -- no longer a primary key ACCOUNT_NAME INTEGER NOT NULL, ACCOUNT_CODE CHAR(5) NOT NULL, ACCOUNT_TYPE VARCHAR(10) NOT NULL, ACCOUNT_OPEN_DATE DATE NOT NULL DEFAULT SYSDATE, ACCOUNT_STATUS VARCHAR(10) NOT NULL DEFAULT ‘ACTIVE’, ACCOUNT_SALESPERSON VARCHAR(30) NOT NULL, IS_DELETED CHAR(1) NOT NULL, CREATED_BY VARCHAR(10) NOT NULL, CREATED_DATE DATE NOT NULL DEFAULT SYSDATE, CREATE_REMARKS VARCHAR(100), LAST_UPDATED_BY VARCHAR(10), LAST_UPDATED_DATE DATE, LAST_UPDATE_REMARKS VARCHAR(100) -- history-specific fields CHANGED_BY VARCHAR(10), CHANGE_DATE DATE, CHANGE_REMARKS VARCHAR(100), OPERATION VARCHAR(10) -–UPDATE/DELETE);
Key Characteristics
- Captures changes that occur to data after it has been inserted
- Audit trail table will contain the original primary key, but that field will cease to be the primary key in the audit trail table Constraint definition on the audit trail table should be sparse and judiciously used. This is a trade-off between ensuring data integrity and not introducing significant overheads.
- The structure of the audit trail may be tuned to cater to special tracking requirements
Externally-Enforced Semantic Integrity Constraints
The robustness of a data model is to some extent dependent on – among other things – the extent to which the data model implicitly enforces integrity constraints – e.g., foreign-key constraints, check constraints, primary-key constraints, UNIQUE constraints and so on.
There are often situations where an integrity constraint needs to be enforced, but cannot be enforced implicitly by the data model definition. These are usually situations that require procedural processing or evaluation of some business logic.
Such integrity constraints are enforced “external” to the data model.
Traditionally, these would be implemented in the application – either at the UI-tier or in the application-tier. With advances in data management technologies and the advent of stored-procedures, these moved closer to the data model and within the database but still “external” to the data model. Contemporary technologies and contemporary perception of “data model definitions” have further served to bring such enforcement closer to the data model, with enhanced capabilities of stored procedures and triggers.
References and Additional Reading Material
* Advanced Data Model Patterns - http://www.essentialstrategies.com/publications/modeling/advanceddm.htm
* Data Modeling - http://en.wikipedia.org/wiki/Data_modeling
* ER Modeling - http://en.wikipedia.org/wiki/Entity-relationship_model
* Normalization - http://en.wikipedia.org/wiki/Database_normalization